Lai starp polinukleotīda un polipeptīda informāciju būtu atbilstība, ir kods: ģenētiskais kods.
Ģenētiskā koda vispārīgās īpašības var uzskaitīt šādi:
Ģenētisko kodu veido trīnīši, un tam nav iekšēju pieturzīmju (Crick & Brenner,).
Tas "tika atšifrēts, izmantojot" atvērto šūnu tulkošanas sistēmas "(Nirenberg & Matthaei, 1961; Nirenberg & Leder, 1964; Korana, 1964).
Tas ir ļoti deģenerēts (sinonīmi).
Kodu tabulas organizācija nav nejauša.
Tripleti "muļķības".
Ģenētiskais kods ir “standarta”, bet ne “universāls”.
Aplūkojot ģenētiskā koda tabulu, jāatceras, ka tas attiecas uz "RNSm tulkojumu uz polipeptīdu, kurā iesaistītās nukleotīdu bāzes ir A, U, G, C. Polipeptīdu ķēdes biosintēze ir nukleotīdu secība aminoskābju secībā.

Katram RNAm bāzes tripletam, ko sauc par kodonu, ir pirmā bāze kreisajā kolonnā, otrā augšējā rindā, trešā labajā kolonnā. Pieņemsim, piemēram, triptofānu (ti, Izmēģiniet), un mēs redzam, ka atbilstošais kodons būs būt kārtībā, UGG. Faktiski pirmā bāze U ietver visu lodziņu rindu augšpusē; šajā gadījumā G identificē labāko lodziņu un pašas kastes ceturto rindu, kur atrodam rakstītu Mēģināt. Līdzīgi, lai sintezētu tetrapeptīdu Leicine-Alanine-Arginine-Serína (simboli Leu-Ala-Arg-Ser), kodā varam atrast kodonus UUA-AUC-AGA-UCA.

Tomēr šajā brīdī jāatzīmē, ka visas mūsu tetrapeptīda aminoskābes ir kodētas (atšķirībā no triptofāna) ar vairāk nekā vienu kodonu. Nav nejaušība, ka tikko sniegtajā piemērā mēs esam izvēlējušies norādītos kodonus. Mēs būtu varējuši kodēt vienu un to pašu tripeptīdu ar citu RNSm secību, piemēram, CUC-GCC-CGG-UCC.
Sākotnēji faktam, ka viena aminoskābe atbilda vairāk nekā tripletam, tika piešķirta nejaušības nozīme, kas izteikta arī koda deģenerācijas termina izvēlē, ko izmantoja, lai definētu sinonīmijas fenomenu. No otras puses, daži dati liecina, ka sinonīmu pieejamība, kas attiecas uz atšķirīgu ģenētiskās informācijas stabilitāti, nebūt nav nejauša. To, šķiet, apstiprina arī konstatējums par atšķirīgu A + T / G + C koeficienta vērtību dažādos evolūcijas posmos. Piemēram, prokariotos, kur mainīguma nepieciešamību neapmierina mendelisma un neomendelisma noteikumi, A + T / G + C attiecībai ir tendence palielināties. Līdz ar to zemāka stabilitāte, saskaroties ar mutācijām, nodrošina lielāku gēnu mutāciju nejaušības iespējas.
Eikariotos, jo īpaši daudzšūnu šūnās, kurās ir nepieciešams, lai viena organisma šūnas saglabātu to pašu iedzimto mantojumu, A + T / G + C attiecībai DNS ir tendence samazināties, samazinot somatisko gēnu mutāciju iespēju .
Sinonīmu kodonu esamība ģenētiskajā kodā rada problēmu, kas jau tika minēta, par antikodonu daudzveidību vai nē RNAt.
Ir skaidrs, ka katrai aminoskābei ir vismaz viens RNSt, taču nav vienlīdz droši, vai viena RNSt var saistīties ar vienu kodonu, vai var vienaldzīgi atpazīt sinonīmus (īpaši, ja tie atšķiras tikai attiecībā uz trešo bāzi).
Mēs varam secināt, ka katrai aminoskābei ir vidēji trīs sinonīmi kodoni, bet antikodoni ir vismaz viens un ne vairāk kā trīs.
Atgādinot, ka gēni ir paredzēti kā ļoti garu DNS polinukleotīdu sekvenču posmi, ir skaidrs, ka viena gēna sākumam un beigām obligāti jābūt atmiņā.
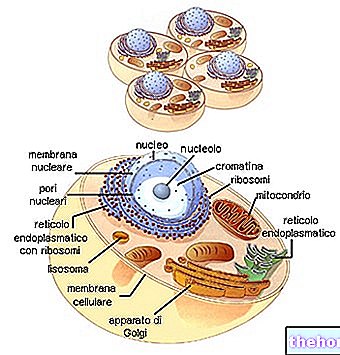
Olbaltumvielu biosintēze
Dažādās DNS daļās ir dubultās ķēdes atvēršana un dažāda veida RNS sintēze.
Iekraušanas posmā RNSt saistās ar aminoskābēm (iepriekš aktivizētas ar ATP un specifisko enzīmu). Biosintētiskā "mašīna" nespēj "labot" nepareizi ielādētas tRNS.
Pēc tam RNSr sadalās divās apakšvienībās un, saistoties ar ribosomu proteīniem, izraisa ribosomu montāžu.
RNS, kas iziet cauri citoplazmai, saistās ar ribosomām, veidojot polisomu. Katra ribosoma, kas plūst uz kurjeru, pakāpeniski uzņem RNSt, kas papildina relatīvos kodonus, uzņemot aminoskābes un veidojot tās saistās ar polipeptīdu ķēdi.
Salīdzinoši stabilais RNS atkal nonāk asinsritē. Atkal tiek izmantotas arī ribosomas, atbrīvojot jau samontēto polipeptīdu.
Sūtnis, kas ir mazāk stabils, jo tas viss ir vienkatonārs, tiek sadalīts (ar ribonukleāzes palīdzību) sastāvdaļās esošajos ribonukleotīdos.
Tādējādi cikls turpinās, viens pēc otra sintezējot polipeptīdus uz kurjera RNS, ko piegādā transkripcija.